Automated Customer Segmentation Model
Directly contributed to an instant 29% increase in membership sales

Problem
Marketing teams know their customers fall into distinct groups but lack an easy way to identify them. Assigning customers into groups via manual segmentation is tedious and doesn't scale, plus insights go stale quickly as customer behaviors change daily. I built a self-serve tool that helps marketers automatically segment their customer lists on an on-demand basis.
Summary
This is an end-to-end machine learning web application that segments customers into meaningful groups for targeted marketing. A user uploads a raw customer-purchase CSV, selects a clustering algorithm (KMeans or a Gaussian Mixture Model), and receives a labeled dataset plus an interactive 3D visualization of the resulting segments. Users do not need a data science background to use this app.
Under the hood, the app runs a full pipeline of custom transformers I wrote for data pruning, cleaning, and feature engineering. Product purchase histories and preferences were one-hot encoded, and the features were compressed to three components with PCA so segments could be visualized in 3D.
To make the tool fast and reproducible, the entire pipeline was pre-trained once and persisted with joblib, so each upload is scored instantly rather than retraining from scratch. All PII was stripped from the dataset before processing, keeping the workflow privacy-safe. The app was containerized with Docker and served in production via gunicorn, and the interactive plots were rendered using client-side JavaScript.
Results
Using a dataset of several thousand users, the model partitioned the customer base into 6 distinct clusters, with fit quality evaluated automatically using silhouette scores and surfaced to the user with plain-English feedback (from "poor fit" through "strong segmentation").
The following plot shows how the customers are distributed in 3D space, with each point colored according to its cluster label. Customers that are closest together are those who have similar product preferences and purchase patterns, and those far apart have very different preferences and purchase patterns.
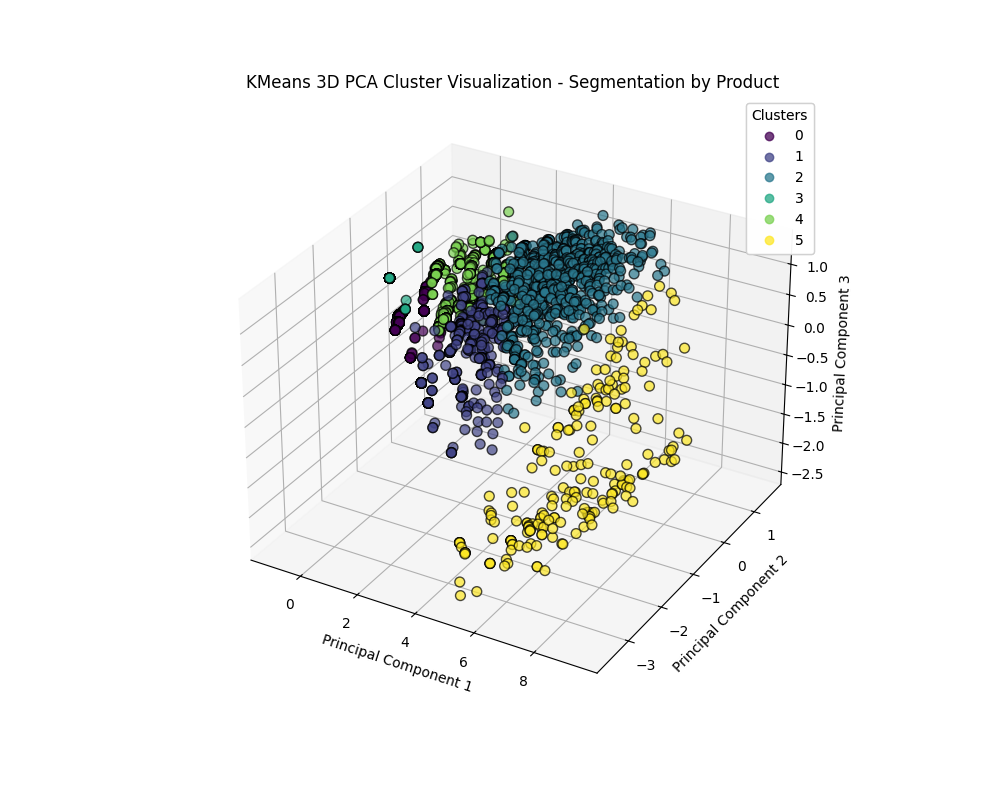
Because the model is unsupervised, it produced the groupings without classifications. The marketing team interpreted and labeled each cluster as a post-processing step, then applied the labeled segments to a live marketing campaign. With each group's characteristics defined, the team could then match product recommendations to customer preferences and target outreach accordingly.
This directly contributed to a 29% increase in membership sales. Plus, due to the fact that the trained pipeline is persisted and reused, marketers can self-serve fresh segmentations in seconds, turning a one-off data-science task into a reusable internal tool.