Fitness Activity Classification ML Model
Correctly identifies gym exercises and number of reps 99.5% of the time
Problem
Gym-goers often dislike having to log their exercises, sets, and reps in a notepad or on their phone because doing so takes away from workout time, and it's also tedious. So I developed a machine learning model that tracks the exercises and reps, so they don't have to.
Summary
This is an in-depth data science project that classifies barbell exercises and counts repetitions from raw wearable-sensor data. The input data is from a 12.5 Hz accelerometer and a 25 Hz gyroscope recorded with a MetaMotion wrist sensor while five participants performed five strength movements: 1) bench presses, 2) squats, 3) rows, 4) overhead presses, and 5) deadlifts. They also performed heavy sets of 5 reps and medium sets of 10 reps.
The raw sensor data was chaotic from both macro- and micro-movements during exercise sets. The data was then time-indexed, merged, and resampled to 200 ms epochs.
I proceeded with cleaning and shaping the chaotic data to increase the signal-to-noise ratio so that a model can learn from it. Specifically, I smoothed out sensor glitches, filtered out high-frequency noise, and engineered features to capture how a movement oscillates over time rather than just its raw values.
To test the model, I benchmarked six classifiers and validated them not just on a random split, but on a held-out participant (i.e., training on four people and testing on a fifth person) to ensure that the model generalizes to someone it had never seen.
Results
Both the Random Forest and neural network models reached 99.5% accuracy on the held-out participant, with XGBoost close behind at 99.1%. I chose Random Forest as the practical model because the neural network was far more computationally intensive for the same accuracy.
The following confusion matrix showed that the Random Forest model only misclassified a small percentage of overhead presses as bench presses, and vice versa. The model correctly identified the other four exercises 100% of the time.
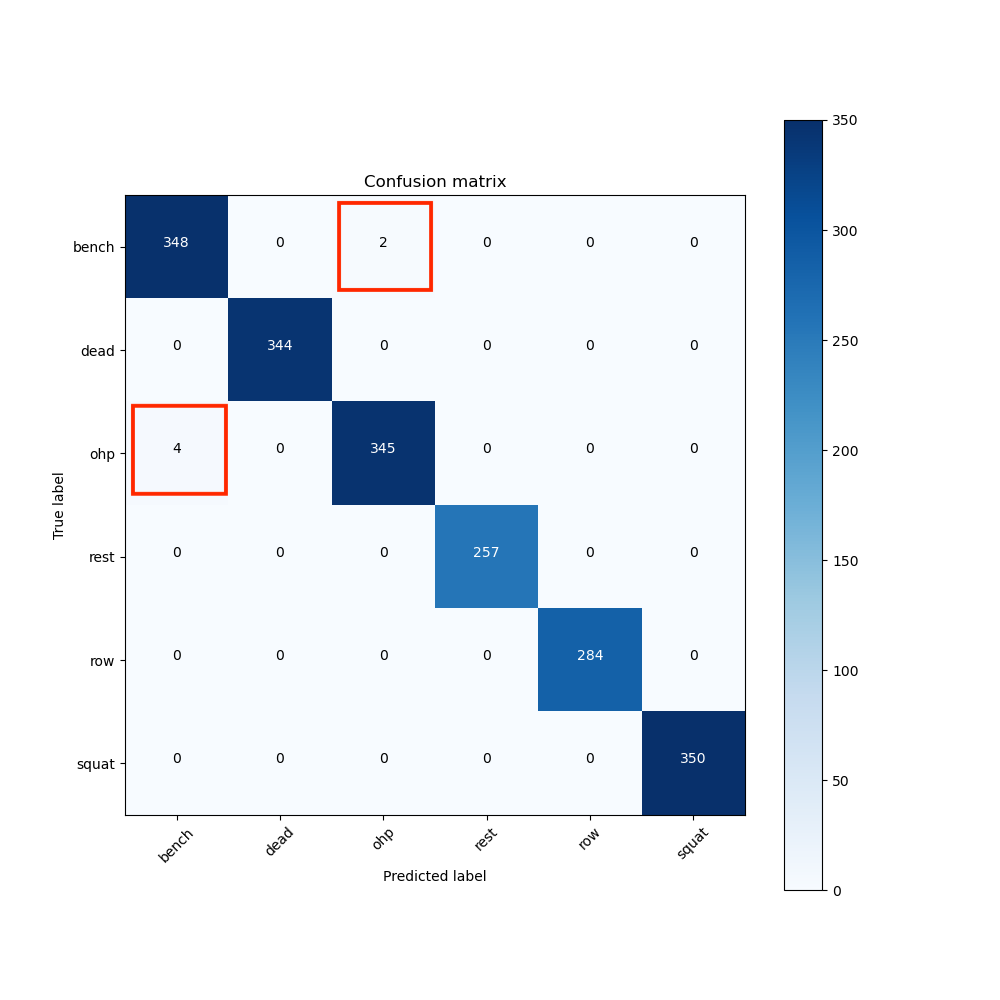
The most interesting part of the results was catching subtle target leakage. On a random 75/25 split, a decision tree model scored 99.7%, which was suspiciously high and I suspected leakage. When I split the dataset by participant, trained the model on four participants and tested on a fifth, the accuracy dropped to 96.9% and exposed a specific failure mode: overhead presses misclassified as bench presses.
Engineering frequency features using Fourier transformation and PCA brought accuracy back up to 99.5%, however. Plus, forward selection confirmed the most predictive signals were frequency-domain components, set duration, gyroscope readings, and the K-Means cluster label, with accuracy approaching 100% using only a handful of them.
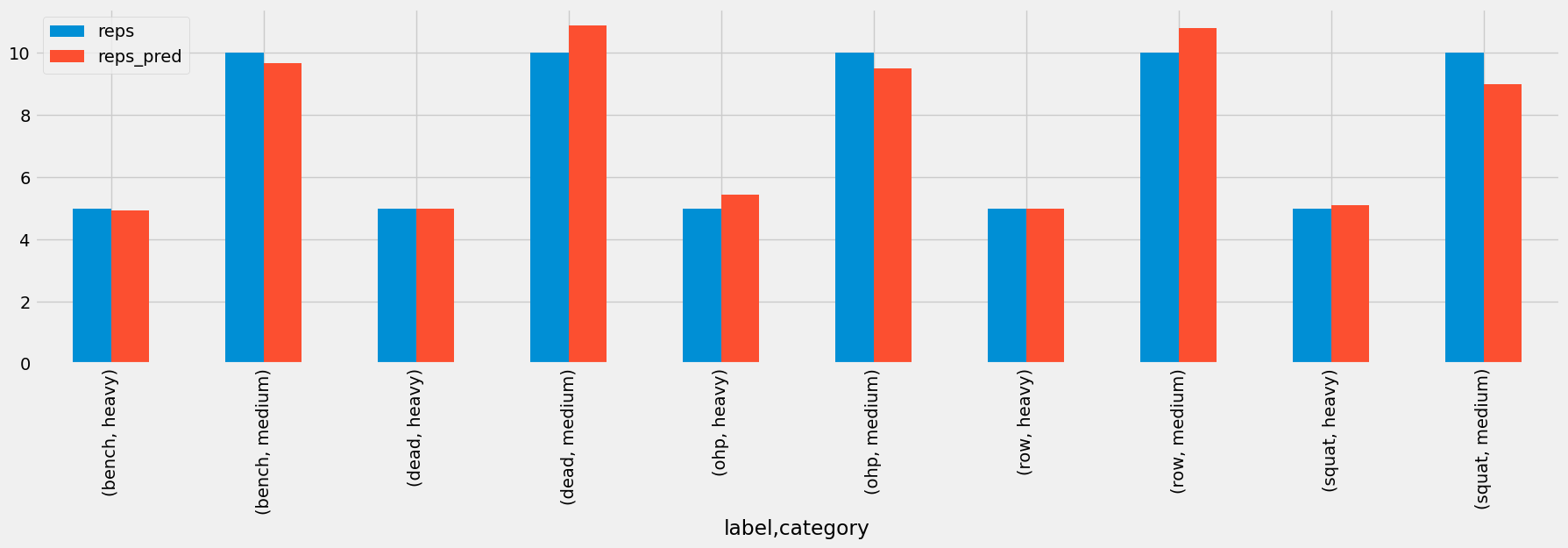
The repetition counter, using per-exercise tuned Butterworth low-pass filters and peak detection, predicted rep counts to within about one repetition of ground truth across every exercise (as shown below).